前陣子從入門到放棄自學機器學習時就有耳聞 Google 推出了許多雲端工具,例如本篇會使用的 BigQuery 等等。
以前自學的時候看到類似的雲端工具時,總會覺得不知該從何處下手才好,最後便下意識地跳過😅
而 Google 最近為了推廣自家的 GCP 雲端平台,發起了 ML Study Jam ,提供免費的一個月線上學習平台 Qwiklabs 訂閱。這次主打的 Qwiklabs 項目會手把手教你如何使用 GCP 上的各項功能,不會涉及到太多機器學習技術探討。 Qwiklabs 會提供一個有時間及功能限制的 GCP 帳號供你練習。在教學中會有一些小關卡,當你在該帳號上完成時就可以過關。
#standardSQL WITH params AS ( SELECT 1AS TRAIN, 2AS EVAL ),
daynames AS (SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
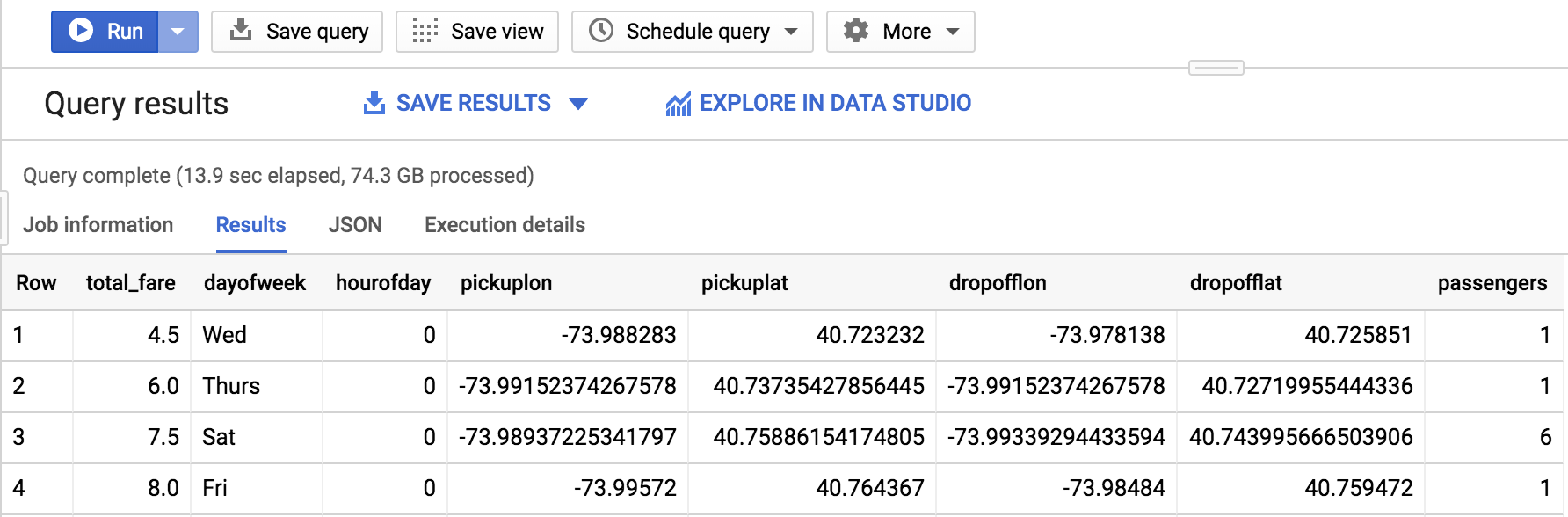
taxitrips AS ( SELECT (tolls_amount + fare_amount) AS total_fare, daysofweek[ORDINAL(EXTRACT(DAYOFWEEKFROM pickup_datetime))] ASdayofweek, EXTRACT(HOURFROM pickup_datetime) AS hourofday, pickup_longitude AS pickuplon, pickup_latitude AS pickuplat, dropoff_longitude AS dropofflon, dropoff_latitude AS dropofflat, passenger_count AS passengers FROM `nyc-tlc.yellow.trips`, daynames, params WHERE trip_distance > 0AND fare_amount > 0 ANDMOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime ASSTRING))),1000) = params.TRAIN )
#standardSQL CREATEorREPLACEMODEL taxi.taxifare_model OPTIONS (model_type='linear_reg', labels=['total_fare']) AS
-- 以下跟上一段的程式碼相同
WITH params AS ( SELECT 1AS TRAIN, 2AS EVAL ),
daynames AS (SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS ( SELECT (tolls_amount + fare_amount) AS total_fare, daysofweek[ORDINAL(EXTRACT(DAYOFWEEKFROM pickup_datetime))] ASdayofweek, EXTRACT(HOURFROM pickup_datetime) AS hourofday, pickup_longitude AS pickuplon, pickup_latitude AS pickuplat, dropoff_longitude AS dropofflon, dropoff_latitude AS dropofflat, passenger_count AS passengers FROM `nyc-tlc.yellow.trips`, daynames, params WHERE trip_distance > 0AND fare_amount > 0 ANDMOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime ASSTRING))),1000) = params.TRAIN )
SELECT * FROM taxitrips
在這段程式碼中,我們創造了一個 model : taxi.taxifare_model ,也就是隸屬於剛創建的 taxi 空間之下。
OPTIONS 指定了 model 的訓練方式以及想預測的目標。
BigQuery ML 目前只提供三種機器學習演算法,分別是 linear_reg 、 logistic_reg 以及 kmeans 。
在這個範例中我們預測的目標是個連續的數值,故線性回歸 linear_reg 符合我們的需求。
演算法本身也有各種的參數可以調整,更詳細的內容就交給 文檔 來解決。
#standardSQL SELECT SQRT(mean_squared_error) AS rmse FROM ML.EVALUATE(MODEL taxi.taxifare_model, (
-- 此處與上上段程式碼雷同,但使用 params.EVAL 作為篩選條件,請看33行
WITH params AS ( SELECT 1AS TRAIN, 2AS EVAL ),
daynames AS (SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS ( SELECT (tolls_amount + fare_amount) AS total_fare, daysofweek[ORDINAL(EXTRACT(DAYOFWEEKFROM pickup_datetime))] ASdayofweek, EXTRACT(HOURFROM pickup_datetime) AS hourofday, pickup_longitude AS pickuplon, pickup_latitude AS pickuplat, dropoff_longitude AS dropofflon, dropoff_latitude AS dropofflat, passenger_count AS passengers FROM `nyc-tlc.yellow.trips`, daynames, params WHERE trip_distance > 0AND fare_amount > 0 ANDMOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime ASSTRING))),1000) = params.EVAL )
SELECT * FROM taxitrips
))
此段使用驗證集 params.EVAL 、 ML.EVALUATE 函數計算推測與正確答案之間的 Root mean square error ,數值越小代表模型越準確。
#standardSQL SELECT * FROM ML.PREDICT(MODEL`taxi.taxifare_model`, (
WITH params AS ( SELECT 1AS TRAIN, 2AS EVAL ),
daynames AS (SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS ( SELECT (tolls_amount + fare_amount) AS total_fare, daysofweek[ORDINAL(EXTRACT(DAYOFWEEKFROM pickup_datetime))] ASdayofweek, EXTRACT(HOURFROM pickup_datetime) AS hourofday, pickup_longitude AS pickuplon, pickup_latitude AS pickuplat, dropoff_longitude AS dropofflon, dropoff_latitude AS dropofflat, passenger_count AS passengers FROM `nyc-tlc.yellow.trips`, daynames, params WHERE trip_distance > 0AND fare_amount > 0 ANDMOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime ASSTRING))),1000) = params.EVAL )
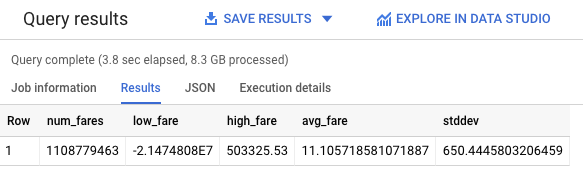
SELECT COUNT(fare_amount) AS num_fares, MIN(fare_amount) AS low_fare, MAX(fare_amount) AS high_fare, AVG(fare_amount) AS avg_fare, STDDEV(fare_amount) ASstddev FROM`nyc-tlc.yellow.trips`
挖賽, Maximum 竟然衝到 503325 ,誰會花這麼多錢搭計程車啊?
我們必須要將這種奇怪的數據清掉!
… …
有書則長,無書則短。最後的篩選如下:
1 2 3 4 5 6 7 8 9
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200 AND pickup_longitude > -75 #limiting of the distance the taxis travel out AND pickup_longitude < -73 AND dropoff_longitude > -75 AND dropoff_longitude < -73 AND pickup_latitude > 40 AND pickup_latitude < 42 AND dropoff_latitude > 40 AND dropoff_latitude < 42
CREATEORREPLACEMODEL taxi.taxifare_model_2 OPTIONS (model_type='linear_reg', labels=['total_fare']) AS
WITH params AS ( SELECT 1AS TRAIN, 2AS EVAL ),
daynames AS (SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS ( SELECT (tolls_amount + fare_amount) AS total_fare, daysofweek[ORDINAL(EXTRACT(DAYOFWEEKFROM pickup_datetime))] ASdayofweek, EXTRACT(HOURFROM pickup_datetime) AS hourofday, SQRT(POW((pickup_longitude - dropoff_longitude),2) + POW(( pickup_latitude - dropoff_latitude), 2)) as dist, #Euclidean distance between pickup and drop off SQRT(POW((pickup_longitude - dropoff_longitude),2)) as longitude, #Euclidean distance between pickup and drop off in longitude SQRT(POW((pickup_latitude - dropoff_latitude), 2)) as latitude, #Euclidean distance between pickup and drop off in latitude passenger_count AS passengers FROM `nyc-tlc.yellow.trips`, daynames, params WHERE trip_distance > 0AND fare_amount BETWEEN6and200 AND pickup_longitude > -75#limiting of the distance the taxis travel out AND pickup_longitude < -73 AND dropoff_longitude > -75 AND dropoff_longitude < -73 AND pickup_latitude > 40 AND pickup_latitude < 42 AND dropoff_latitude > 40 AND dropoff_latitude < 42 ANDMOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime ASSTRING))),1000) = params.TRAIN )